Building highly available Microservices @ Reputation
In Microservices environments some times we have to build mission critical services which can’t take any downtimes. In Reputation, we have such a use case with a service called Governor. In this blog, I’ll talk about how we made the Governor highly available with almost zero downtime.
In Reputation, we interact with many 3rd party APIs to push/pull data and these API calls happen from many different backend services. Almost all the API providers we interact with have strict rate-limiting policies. So it’s very important to make sure the rate at which we make calls is under the given capacity, at the same time utilizing the available capacity to a maximum extent. As multiple services make calls to the same API it’s important to have a common bookkeeping service that keeps tracks of all calls we are making and make sure the combined number of calls from different services is under the available capacity, that’s why we build the service Governor whose responsibility is to make sure the combined number of hits from all services to an API is under the given capacity.
Governor has a client driver using which the services interact with Governor. At a high level, the Governor client offers two methods to interact with, they are getPermit() and releasePermit(). The getPermit() gives a permit when it’s ready based on the availability.
Now you might have understood that the Governor service is one of the mission-critical services and any service interruptions in Governor will impact all the communications to external APIs in reputation. To make the service highly available we have followed few approaches that are described below.
Primary/ Secondary model:
The state in Governor service is in-memory, we did this because the concurrent requests to this service are very high. So instead of persisting the state to any database, we went with keeping in-memory. The downside of this is we can’t scale the service horizontally. To maintain the high availability in case of server outages we went with a primary/secondary model where based on the Redis based locking system one of the Governor servers becomes primary and all the secondary nodes proxy the requests to primary.
Client offline capabilities:
In case everything listed above fails still we don’t want our backend services to pause, to achieve that we build offline capabilities within the client drivers where the client driver continues to give permits at a certain rate even though the Governor service is not reachable. Let me explain the offline capabilities with an example. Following is one of the Throttle definition we have in the Governor
{
"id": "gmbv4_insights",
"limitType": "RateLimit",
"permitsPerSecond": 25
}
This means at most we can make 25 calls per second to an API type called gmbv4_insights. We have given configurable options at the client driver level so that the service users can decide at which rate they can still get the permits even though the server is completely down. The configurations look like following
offlineSupport: true,
offlineFactor: 0.25
If service users choose to enable offline support, they need to pass the offline factor value which is between 0 to 1. If offline support enabled, then in situations where the client unable to reach the server for any reasons like network issues/ server downs, etc., then the client driver falls back to the offline mode and does all the bookkeeping to keep giving permits. This way the service users will continue doing their operations at a lower speed than completely halting the execution. As and when the Governor server is back the requests will be sent to the Governor.

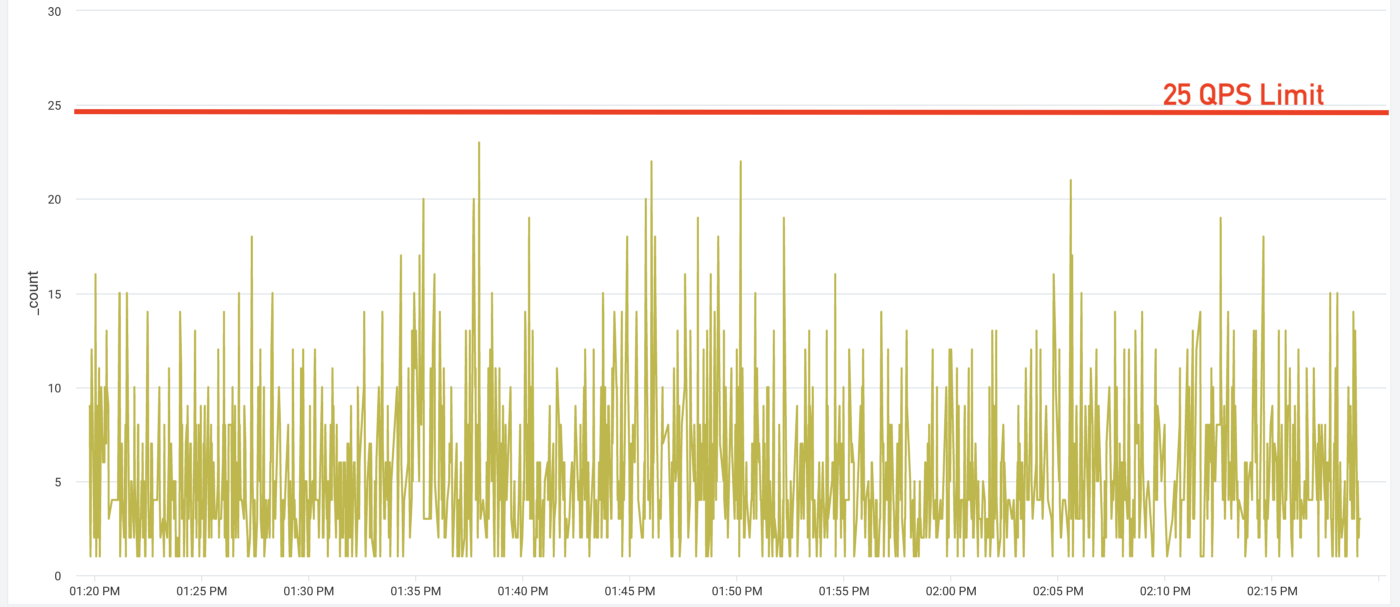
As we can see from our logs in the last 30days, there are times where there are short service disruptions and the clients continued to run their requests by getting the permits from the Governor client using offline mode.
These are some of the approaches we took to provide the highest availability for some of our mission-critical services.
Originally posted @
https://engineering.reputation.com/building-highly-available-microservices-e903ce497452